TODO
总结面试中项目中被问懵逼的点,补充到项目里
spring事务
rocketmq事务消息实现
一致性hash算法
程序设计
- 一次请求追踪链路traceId的几个点
- 首先在日志中追踪traceId(将traceId放入到MDC中)
- 跨线程场景:
- 父子线程场景,使用InheritableThreadLocal
- 线程池场景,包装task或包装线程池,在线程池或task调用前放入tradeId
- 跨进程场景:
- 远程调用时如何在dubbo中追踪traceId(编写一个filter,写到rpccontext的attachment中)
- 如何在rocketmq中追踪traceId(消息发送前后拦截器+message的properties)
- rocketmq发送批量消息
- rocketmq发送任意时长的消息
- 排查系统慢
- 某些场景慢,压测复现慢的场景,收集统计运行情况,单独分析和优化
- 所有的都很慢
- 网络层面
- 网络延迟:网络是否有延迟
- 带宽限制:带宽是否到达上限
- DNS解析:DNS查询是否耗时过长
- CDN问题:使用了CDN的话,检查CDN是否正常工作
- 服务器层面
- 服务器负载:CPU、内存、磁盘IO使用率是否过高
- 连接数限制:检察服务器最大连接数
- 垃圾回收:检查GC日志,是否有频繁GC或长时间GC
- 应用代码层面
- 同步锁竞争:是否有过多的锁竞争导致线程阻塞
- 数据库查询:检查SQL执行计划,是否有慢查询
- 序列化/反序列化:是否耗时
- 调整程序运行顺序
- 同步能否改异步
- 多个不关联的任务,是否可以同时调用执行
- 是否由三方接口或远程接口导致
- 数据量大导致,分页,作缓存,压缩
- 数据库层面
- 索引是否合理,是否未走索引
- 表锁/行锁是否等待时间过长
- 连接池是否可以调整
- 单表时间量是否过大
- 外部依赖
- 第三方API,调用外部API是否过慢
- 微服务调用,链路是否过长
- 消息队列积压或消费慢
- 网络层面
- 线程池核心线程为什么不会被销毁
- 线程池的核心线程参数设置
- 线程池的拒绝策略怎么设置的
- JDK常见的一些容器,并发容器,它们的一些特性。并发控制怎么做
- Innodb执行流程,redo日志,undo日志,binlog日志以及mvvc多版本并发控制
- Rpc框架需要注意哪些方面
- Spring循环依赖
- Jvm收集器,清除算法,G1收集器
- Spring IOC、AOP介绍一下
- Spring的@Autowired,@Value,以及JDK的@Resources,@PostConstruct,@PreDestroy如何处理的
AbstractAutowireCapableBeanFactory的populateBean负责根据属性填充对象- @Autowired,@Value是Spring自带的注解,通过
AutowiredAnnotationBeanPostProcessor处理的 - @Resources,@PostConstruct,@PreDestroy等JDK注解,通过
CommonAnnotationBeanPostProcessor处理
- Spring Starter 是怎么被加载的,有哪些不常用的注解(@Conditional)
- Spring 事务传播机制
- 幂等设计
- 幂等是指同一操作多次执行结果产生影响和多次一样
- 场景:
- 前端重复提交表单。服务器下发一个token,前端携带token请求服务器,服务器验证token是否存在,处理请求后删除token
- 数据库插入幂等,唯一索引保证。更新幂等,带着版本号去更新
- RPC调用幂等,客户端携带唯一请求ID去请求,服务端记录唯一请求ID
- MQ消费幂等,1以消息唯一标识来做,存储唯一标识。2以业务唯一标识来做比如订单号
索引的数据结构都有哪些,hash和btree
netty网络模型是怎么样的
dubbo线程模型是怎样的
mysql的索引数据类型,以及你能想到的优化点
mysql的联合索引ABC,关于order by能不能用索引,需要看查询索引的结果,对于order by的列是不是有序的,如果是有序地就可以用上,如果无需就只能文件排序
计算机网络
TCP协议
三次握手
目的:通过同步双方序列号,保证双方收发功能正常。过程如下:
发送端 -> SYN=1,seq=x -> 服务端
发送端 <- SYN=1,ACK=1,seq=y,ack=x+1 <- 服务端
发送端 -> ACK=1,seq=x+1,ack=y+1 -> 服务端
四次挥手
TCP链接是全双工的,每个方向都要断开。主动发送方过程如下:
主动关闭方 -> FIN=1,seq=u -> 被动关闭方
主动关闭方 <- ACK=1,ack=u+1 <- 被动关闭方 (此时主动关闭方不再发送数据,但还可接收数据)
主动关闭方 <- FIN=1,seq=v <- 被动关闭方
主动关闭方 -> ACK=1,seq=v+1 -> 被动关闭方
流量控制(滑动窗口)
TCP报文首部中有一个16位的“窗口大小”字段值,用于告知对方:“我当前还能接收多少字节的数据”
- 这个值被称为“接收窗口(receive windows也就是rwnd)”
- 发送方根据这个值动态调整自己可发送但尚未被确认的数据量,确保不超过接收方处理能力
滑动窗口机制
发送方视角中,窗口的三个区域
| 区域 | 说明 |
|---|---|
| 已发送且已确认 | 可以释放,窗口向前滑动 |
| 已发送但未确认 | 正在等待ACK,占窗口空间 |
| 可发送但未发送 | 在接收窗口范围内,可立即发送 |
| 不可发送 | 超出接收窗口,需要等待 |
接收方如何更新窗口?
每次发送ACK时,接收方都会将可用缓冲区大小填入到TCP报文首部的“windows”字段中
例如:接收方缓冲区大小为64KB,已接收但应用未读取数据40KB,那rwnd = 64KB - 40KB = 24KB,可用缓冲为24KB,则发送方最多可发送24KB数据
拥塞控制
目的:防止网络链路过载(全网视角看网络状态),让发送方根据当前网络承载能力,动态调整发送速率,充分利用带宽的同时防止压垮网络
TCP拥塞控制核心思想
TCP无法判断网络是否拥塞,但可以通过间接信号来判断:
- 丢包(超时重传或收到重复ACK) -> 可能是路由器缓存满了而丢包 -> 网络拥塞了
- RTT(往返时延)变长 -> 队列排队时间变长 -> 网络拥塞了
于是TCP设计了一种“试探+回退”的思路:
- 慢慢试探,一开始发送少量数据包,逐渐增加发送量
- 发生拥塞了(如丢包),大幅减少数据包发送量
- 再慢慢地恢复
拥塞窗口(核心机制)
TCP引入了一个虚拟的窗口 —— 拥塞窗口(Congestion Window, cwnd)
发送方能发送的数据量受限于两个窗口的最小值,即:实际发送量 = min(接收窗口 rwnd, 拥塞窗口 cwnd)
OSI七层模型
物理层 -> 数据链路层 -> 网络层 -> 传输层 -> 会话层 -> 表示层 -> 应用层
网络编程
阻塞IO
一条线程处理一个连接,发起IO请求后,在数据没有返回前会一直阻塞。效率低下,造成浪费
非阻塞IO
进程发起IO操作时,如果数据没准备好不会阻塞线程,而是返回。通过轮询来实现,可能会造成CPU空转
IO多路复用
解决CPU空转问题,线程阻塞在“等待IO事件”上,有IO事件时会立即返回。用一个线程来等待多个IO,有数据了就去处理,避免阻塞、轮询适合高并发
实现:linux的epoll
IO多路复用是系统内核层面的机制
事件驱动
程序注册好要关注的事件,循环等待,事件就绪就处理。
事件驱动 = 事件循环(event loop) + 事件分发(dispatcher) + 事件处理(handler)
事件驱动是应用程序层面的模型,一般和IO多路复用来配合,用作高并发事件处理
Reactor模型
组件
Reacotr:事件分发器,用IO多路复用来等待时间(epoll,select),将事件分发给handler
Acceptor:处理连接事件
Handler:处理IO读写事件
工作流程
Reactor接收到连接事件,调用acceptor处理。接收到读写事件,调用对应handler处理
模型变种
单Reactor单线程:事件分发+连接、读写处理都在一个线程里,性能有限
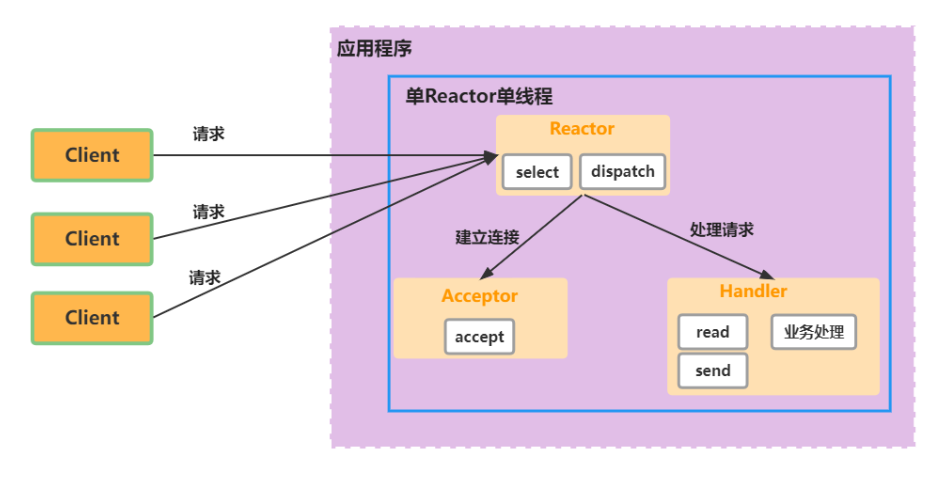
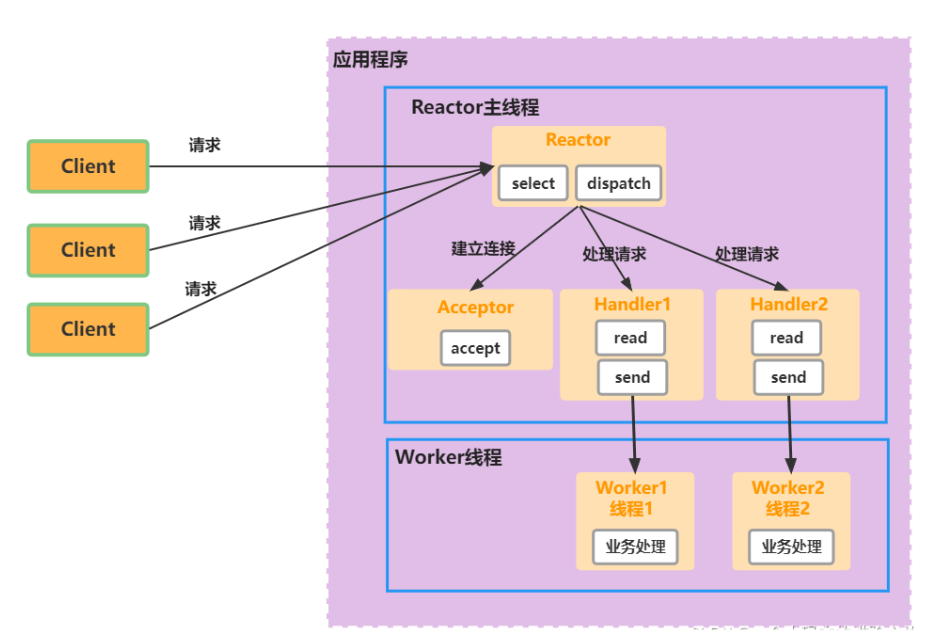
单Reactor多线程:Reactor负责事件分发+连接、读写处理,只不过业务逻辑的处理提交到了线程池
- 性能得到提升,弊端是当事件正在读写时,对其他事件来说此时线程是阻塞的,连接过多时会有性能问题
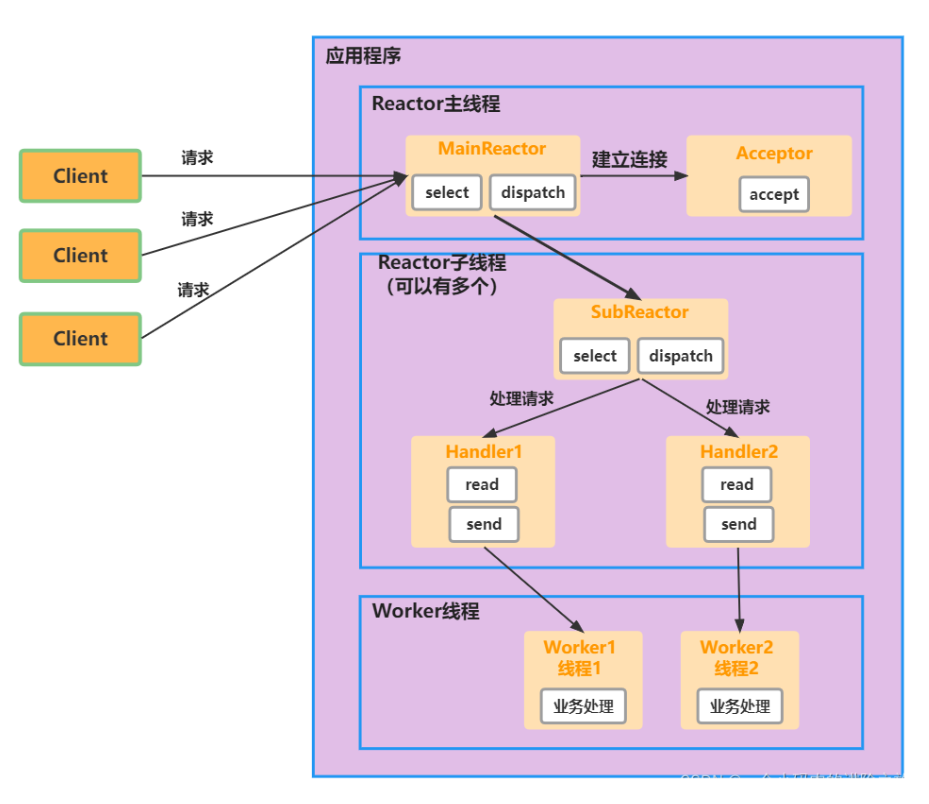
多Reactor多线程(主从Reactor多线程):主Reactor负责连接处理,并将selector分发给子Reactor。子Reactor负责对应连接的读写事件,有自己的业务线程池
数据库
存储引擎Myisarm和Innodb的区别
myisarm不支持事务、innodb支持事务
事务的四个特性
原子性、一致性、持久性、隔离性
innodb如何支持事务四个特性
innodb插入、修改SQL的过程
- 先加锁,锁行或者锁表
- 修改的数据页没在内存里,加载到内存里
- 生成undo log,记录修改前数据,方便回滚
- 从内存中修改数据
- 生成redo log到redo log buffer
- redo log落盘(根据策略决定是否落盘时机),事务提交
- 解锁
- 内存中的脏页(修改完的数据),根据策略决定什么时候落盘
- 标记redo log记录执行完成
undo log和redo log的作用
undo log用来回滚日志和历史查询,redo log用来重做日志(mysql异常宕机时)
隔离级别
读未提交:存在脏读问题
读已提交:存在不可重读问题
可重读:通过mvcc和间隙锁解决幻读问题
序列化:SQL排队处理,效率低下
MVCC多版本并发控制
MVCC 是 Mysql 实现高并发读写的一种机制,由隐藏字段(trx_id)+ undo log + read view 实现
隐藏字段:innodb 每行数据变更后维护的元数据,trx_id最后一次修改数据的事务ID
undo log:记录数据的值的修改历史
read view:读视图,在事务启动时生成,记录【活跃事务ID集合以及min_trx_id(最小活跃事务id),max_trx_id (当前系统下一个将要分配的 ID)】。决定事务能看到哪些版本的数据
- RR级别下,只生成一次读视图。RC级别下,每次查询会生成一次读视图
工作原理(RR级别):
T1查询某行数据是,会看到该行的trx_id
1)trx_id >= max_trx_id,说明数据是在读视图生成后,进行修改的,不可见,需要回溯undo log
2)trx_id 在活跃事务ID集合中,说明数据未提交,不可见,回溯undo log
3)trx_id < min_trx_id,说明数据是在读视图生成前,进行修改的,可见
SQL优化例子
全表扫描 -> 联合索引命中
这条SQL只有索引user_id单列索引,造成了filesort。我们可以创建联合索引user_id,status,create_time,索引过滤 + 排序一次完成,提升响应时间
select *
from order
where user_id = ?
and status = ?
order by create_time desc
limit 10避免在索引上做函数
假设我们有索引create_time,但因为在字段上做了函数操作,导致索引失效。我们可以改写SQL
SELECT *
FROM user
WHERE DATE(create_time) = '2025-01-01'Redis
rdb和aof的优缺点以及原理
rdb是生成某一时刻内存快照
- 优点:文件小(dump.rdb),恢复速度快
- 缺点:丢失生成那一刻之后的数据
aof是命令追加的形式,执行命令后,会将命令追加到appendonly.aof文件中
- 优点:数据更安全(基本无丢失),可读性强,文件人类可读
- 缺点:文件较大,恢复速度慢,写入开销较大
原理:rdb和aof都是使用fork()子进程 + COW(copy on write)技术,
- COW:fork()子进程后,父子进程共享同一份内存数据。当有修改操作时,会复制被修改的内存页到新内存,保证共享内存数据不被修改
rdb流程:
- redis调用fork()创建子进程
- 子进程将内存数据写入到临时rdb文件
- 用临时rdb文件替换旧的rdb文件
- 主线程继续处理命令,不受影响
aof流程:
- 执行redis命令后,将命令数据追加到aof缓冲区
- 根据刷盘策略,将数据刷入磁盘文件appendonly.aof中
- 重写机制(rewrite):
- fork()子进程,扫描内存数据
- 生成最少得命令写入aof文件
- 替换旧的aof文件
string数据结构
sds简单动态字符串,记录了字符串的长度
list数据结构
list是有序集合,链表结构,按插入顺序排序。从redis 3.2+开始,使用quicklist(双向链表 + ziplist)来实现。双向链表每一个节点都是一个ziplist,各个节点组成双向链表
优点:ziplist可以存储多个元素,节省内存,可以快速左右删除、插入
缺陷:随着节点增多,可能存在深层节点遍历慢的问题。ziplist中间插入删除效率较低
set数据结构
set是无序不重复集合。数据结构由intset或hashtable组成,取决于元素的数量
intset:有序的整数数组
- 优点:节省内存,查询效率高,查询时间复杂度O(1)
- 缺点:不能存储字符串
hashtable:查询效率高,时间复杂度O(1)
zset数据结构
zset是带有score的有序集合类型,由hashtable+skiplist组成
hashtable:查询某个key的value及score,时间复杂度O(1)
skiplist:多层有序链表,通过score查询对应value,时间复杂度O(logn)
hash数据结构
hash的数据结构为ziplist或hashtable,取决于元素的数据或长度
ziplist:节省内存,数据小查询效率高
hashtable:
rehash与渐进式扩容
rehash其实是hashtable的扩容或者缩容,将老表的数据迁移到新的哈希表过程。又因为redis是单线程的,迁移时会造成阻塞,为了减少阻塞时间,就有了渐进式扩容
渐进式扩容:每次执行普通命令(get/set等)时,都会顺便迁移一个或多个桶(bucket)
- hash数据查询,如果在进行rehash,则需要查两个表,即新表和旧表
- 直至所有桶迁移完毕,用新表替代老表
- 好处是减少阻塞,用户无感
主从复制
主从节点数据数据同步方案是全量同步 + 增量同步。先传输rdb文件做全量同步,然后通过replication buffer来增量同步
replication buffer
replication buffer是一段环形缓冲区,固定大小,默认1M,存储写命令。从节点根据自身的replication offset去replication buffer中拿取数据。如果offset不在buffer中,则说明从节点落后太多数据,除非全量同步
redis cluster
核心思想
数据分片、主从、高可用、自动故障检测与恢复、支持在线扩/缩容
数据分片
使用hash slot(哈希槽)进行分片,redis将key空间划分为16384个slot,并将这些slot均匀分布在cluster的主节点上。slot与主节点映射在客户端缓存,
- redis client本地会缓存slot与节点映射,但本地映射错误时,节点会返回“MOVED 新节点”指令。当slot正在迁移时,节点可能会返回“ASK 节点”
通过gossip协议 + 心跳检测来实现故障检测
过程:主观下线 -> 客观下线 -> 故障转移
主观下线:某个节点发现另一节点超时未响应,标记为主观下线
客观下线:这个节点通过gossip协议广播节点主观下线信息,超半数节点认为主观下线时,变为客观下线
故障转移:目标从节点发起选举,获多数节点投票,升级为主节点。更新slot归属,通知客户端
在线扩/缩容
redis cluster支持在线扩缩容,但cluster不负责slot信息的转移
扩容:新加入主节点,用户从现有主节点迁移部分slot到加入的主节点
缩容:将退出主节点slot迁移到其他主节点中,然后退出主节点
RocketMQ
集群模式
传统主从:一主一从或一主多从。无法自动故障转移,数据异步复制可能丢消息,同步复制效率低下,运维复杂需要人工指定主从
diedger集群:同一broker group中节点对等。自动选主,消息同步到大多数节点存储成功才会返回成功,采用Raft算法选主,运维简单
| 特性 | 传统主从 | Diedger集群 |
|---|---|---|
| 自动选主 | 不支持,手动调整 | 支持 |
| 消息强一致 | sync模式 | 原生支持 |
| 可靠性 | async模式可能丢 | 多数节点确认 |
| 自动运维 | 不支持 | 支持 |
| 适用场景 | 简单部署,性能高效 | 强一致性、金融、云原生 |
延时消息
延时消息由预定义延时等级 + 系统内部延时队列(SCHEDULE_TOPIC_XXX)实现,不支持任意精度的延时。
基本流程:
- 生产者发送延时消息,指定延时级别(delayLevel)
- broker收到延时消息,不直接投递到目标Topic,而是将其写入到内部特殊Topic(SCHEDULE_TOPIC_XXX,该Topic内部有18个队列)
- broker后台有一个ScheduleMessageService服务,timer线程以固定周期扫描每个队列
- 当消息“到期时间” <= 当前时间,timer将消息重新投递到目标Topic,消费者可正常消费
public class ScheduleMessageService extends ConfigManager {
private static final long FIRST_DELAY_TIME = 1000L;
private static final long DELAY_FOR_A_WHILE = 100L;
private static final long DELAY_FOR_A_PERIOD = 10000L;
// 延迟级别(1s:1000,2s:2000 ...)
private final ConcurrentMap<Integer /* level */, Long/* delay timeMillis */> delayLevelTable = new ConcurrentHashMap<Integer, Long>(32);
// 偏移量
private final ConcurrentMap<Integer /* level */, Long/* offset */> offsetTable = new ConcurrentHashMap<Integer, Long>(32);
private Timer timer;
public void start() {
if (started.compareAndSet(false, true)) {
super.load();
this.timer = new Timer("ScheduleMessageTimerThread", true);
for (Map.Entry<Integer, Long> entry : this.delayLevelTable.entrySet()) {
Integer level = entry.getKey();
Long timeDelay = entry.getValue();
// 根据延时级别获取消息队列消费进度,说明每个延时级别对应一个消息队列
Long offset = this.offsetTable.get(level);
if (null == offset) {
offset = 0L;
}
// 启动时,延时1s执行调度任务
if (timeDelay != null) {
this.timer.schedule(new DeliverDelayedMessageTimerTask(level, offset), FIRST_DELAY_TIME);
}
}
// 每10s持久化延时消息队列进度
this.timer.scheduleAtFixedRate(new TimerTask() {
@Override
public void run() {
try {
if (started.get()) {
ScheduleMessageService.this.persist();
}
} catch (Throwable e) {
log.error("scheduleAtFixedRate flush exception", e);
}
}
}, 10000, this.defaultMessageStore.getMessageStoreConfig().getFlushDelayOffsetInterval());
}
}
class DeliverDelayedMessageTimerTask extends TimerTask {
public void run() {
try {
if (isStarted()) {
this.executeOnTimeup();
}
} catch (Exception e) {
// XXX: warn and notify me
log.error("ScheduleMessageService, executeOnTimeup exception", e);
ScheduleMessageService.this.timer.schedule(new DeliverDelayedMessageTimerTask(
this.delayLevel, this.offset), DELAY_FOR_A_PERIOD);
}
}
public void executeOnTimeup() {
// 根据延时消息主题和消息队列Id拿到消息队列
ConsumeQueue cq =
ScheduleMessageService.this.defaultMessageStore.findConsumeQueue(TopicValidator.RMQ_SYS_SCHEDULE_TOPIC,
delayLevel2QueueId(delayLevel));
......
for (; i < bufferCQ.getSize(); i += ConsumeQueue.CQ_STORE_UNIT_SIZE) {
...
long now = System.currentTimeMillis();
// 消息需要发送时间(消息真实的发送时间 + 延迟时间)
long deliverTimestamp = this.correctDeliverTimestamp(now, tagsCode);
// 是否需要发送(消息真实的发送时间 + 延迟时间) - now
long countdown = deliverTimestamp - now;
if (countdown <= 0) {
// 消息已经达到延时了,该发送出去了
MessageExt msgExt =
ScheduleMessageService.this.defaultMessageStore.lookMessageByOffset(
offsetPy, sizePy);
if (msgExt != null) {
try {
// 恢复真实主题和消息队列Id
MessageExtBrokerInner msgInner = this.messageTimeup(msgExt);
if (TopicValidator.RMQ_SYS_TRANS_HALF_TOPIC.equals(msgInner.getTopic())) {
log.error("[BUG] the real topic of schedule msg is {}, discard the msg. msg={}",
msgInner.getTopic(), msgInner);
continue;
}
// 发送消息到broker
PutMessageResult putMessageResult =
ScheduleMessageService.this.writeMessageStore
.putMessage(msgInner);
if (putMessageResult != null
&& putMessageResult.getPutMessageStatus() == PutMessageStatus.PUT_OK) {
if (ScheduleMessageService.this.defaultMessageStore.getMessageStoreConfig().isEnableScheduleMessageStats()) {
ScheduleMessageService.this.defaultMessageStore.getBrokerStatsManager().incQueueGetNums(MixAll.SCHEDULE_CONSUMER_GROUP, TopicValidator.RMQ_SYS_SCHEDULE_TOPIC, delayLevel - 1, putMessageResult.getAppendMessageResult().getMsgNum());
ScheduleMessageService.this.defaultMessageStore.getBrokerStatsManager().incQueueGetSize(MixAll.SCHEDULE_CONSUMER_GROUP, TopicValidator.RMQ_SYS_SCHEDULE_TOPIC, delayLevel - 1, putMessageResult.getAppendMessageResult().getWroteBytes());
ScheduleMessageService.this.defaultMessageStore.getBrokerStatsManager().incGroupGetNums(MixAll.SCHEDULE_CONSUMER_GROUP, TopicValidator.RMQ_SYS_SCHEDULE_TOPIC, putMessageResult.getAppendMessageResult().getMsgNum());
ScheduleMessageService.this.defaultMessageStore.getBrokerStatsManager().incGroupGetSize(MixAll.SCHEDULE_CONSUMER_GROUP, TopicValidator.RMQ_SYS_SCHEDULE_TOPIC, putMessageResult.getAppendMessageResult().getWroteBytes());
ScheduleMessageService.this.defaultMessageStore.getBrokerStatsManager().incTopicPutNums(msgInner.getTopic(), putMessageResult.getAppendMessageResult().getMsgNum(), 1);
ScheduleMessageService.this.defaultMessageStore.getBrokerStatsManager().incTopicPutSize(msgInner.getTopic(),
putMessageResult.getAppendMessageResult().getWroteBytes());
ScheduleMessageService.this.defaultMessageStore.getBrokerStatsManager().incBrokerPutNums(putMessageResult.getAppendMessageResult().getMsgNum());
}
continue;
} else {
// XXX: warn and notify me
log.error(
"ScheduleMessageService, a message time up, but reput it failed, topic: {} msgId {}",
msgExt.getTopic(), msgExt.getMsgId());
ScheduleMessageService.this.timer.schedule(
new DeliverDelayedMessageTimerTask(this.delayLevel,
nextOffset), DELAY_FOR_A_PERIOD);
ScheduleMessageService.this.updateOffset(this.delayLevel,
nextOffset);
return;
}
} catch (Exception e) {
/*
* XXX: warn and notify me
*/
log.error(
"ScheduleMessageService, messageTimeup execute error, drop it. msgExt={}, nextOffset={}, offsetPy={}, sizePy={}", msgExt, nextOffset, offsetPy, sizePy, e);
}
}
} else {
// 进行下次定时任务处理的放入
ScheduleMessageService.this.timer.schedule(
new DeliverDelayedMessageTimerTask(this.delayLevel, nextOffset), countdown);
// 更新延时消息的消费进度
ScheduleMessageService.this.updateOffset(this.delayLevel, nextOffset);
return;
}
}
......
}
}
}JVM
CMS收集器
工作流程
初始标记STW -> 并发标记 -> 重新标记STW -> 并发清除
核心思想
最小化STW
CMS收集器的缺陷
- cpu资源敏感:默认启用(cpu核数 + 3)/ 4个线程去进行垃圾收集,在cpu核数较少时,会占用大量cpu并降低吞吐量
- 无法处理浮动垃圾:在“并发标记”和“并发清除阶段”产生的垃圾,cms是无法去处理的,只能等待下次gc。如果并发回收时,老年代空间不够用,jvm会暂停所有线程,启动serial old(单线程)收集器进行垃圾回收,造成STW
- 内存碎片问题:由于使用“标记清除”算法,会产生内存碎片,解决方案是每次full gc都进行压缩整理,但治标不治本,full gc时可能已经产生了很多内存碎片,且full gc代价极大
- old gc是老年代gc,full gc是全代gc,old gc ∈ full gc
G1收集器
工作流程
初始标记STW -> 并发标记 -> 最终标记STW -> 筛选回收STW
核心思想
在可控停顿时间内,获得尽可能高的吞吐量
关键创新
将堆内存分为多个大小相等的region(ps:逻辑上还是新生代和老年代)
采用“标记 + 复制整理”算法,天然无内存碎片
使用Remember Set(RSet)跟踪跨region引用(大对象会跨region)
收集时如何达到期望停顿时间
在“筛选回收”阶段,G1会统计收集哪些region可达到期望停顿时间
为什么没有内存碎片
使用“标记 + 复制”算法,将存活对象转移到空闲region上,老region直接清除
Java基础
ArrayList使用注意点,扩容包含分配新数组和数据迁移,频繁扩容会带来额外开销。所以在频繁添加数据的情况下,最好提前指定容量
public boolean add(E e) {
ensureCapacityInternal(size + 1); // 确保容量够用
elementData[size++] = e;
return true;
}
private void ensureCapacityInternal(int minCapacity) {
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1); // 1.5倍
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity; // 保证最小容量
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity); // 特殊处理极大数组
elementData = Arrays.copyOf(elementData, newCapacity);
}ConcurrentHashMap的特点
jdk1.8数据结构为数组+链表/红黑树,插入数据是通过CAS+Synchronized保证线程安全。cas保证数组线程安全,Synchronized保证链表和红黑树线程安全。扩容则是按区段划分锁,多个线程同时去迁移数据。获取元素不用加锁,通过volatile来保证数据多线程可见
Reentrantlock的特点及应用场景
为什么clh头结点是空的
ThreadLocal
ThreadLocal结构
每条线程都有有一个ThreadLocalMap,这个Map的Key是弱引用的ThreadLocal
为什么ThreadLocal被设计成弱引用
因为强引用会导致内存泄漏。假设有以下情况,ThreadLocalMap强引用ThreadLocal,而用户程序中引用TL的对象被回收,但因为TL被TLM强引用,会导致TL永不会回收
TL一般怎么使用
使用static修饰,防止被回收。使用完及时清理,防止内存泄漏
父子线程的ThreadLocal值如何拷贝?inheritableThreadLocals
inheritableThreadLocals继承自ThreadLocal,在子线程创建时,会将父线程的inheritableThreadLocals拷贝到子线程inheritableThreadLocals中
ThreadPoolExecutor
线程池核心线程为什么不会被销毁
核心线程是否被销毁,取决于参数allowCoreThreadTimeOut。当允许核心线程获取超时 或 当前线程数>核心线程时,核心线程才会被销毁
线程池的核心参数
线程池核心参数有:核心线程数、最大线程数、非核心线程存活时间(等待新任务最长时间)、存活时间单位、工作队列、线程工厂、拒绝策略
拒绝策略
CallerRunsPolicy:调用方执行
AbortPolicy:中止策略,直接抛出拒绝异常
DiscardPolicy:丢弃策略,直接丢弃任务
DiscardOldestPolicy:丢弃最老任务策略,丢弃到工作队列中最老的任务
ScheduleThreadPoolExecutor
由delayedWorkQueue(小顶堆结构) + ScheduledFutureTask 构成核心
- [ ] delayedWorkQueue的siftDown方法,以及leader线程作用
- [ ] delayedWorkQueue的数据结构,最小堆算法,根据延迟时间进行排序
Spring
一条请求在Spring中经过哪些流程
- 先经过servlet自带的filter
- 然后进入到spring的dispatcherServlet中
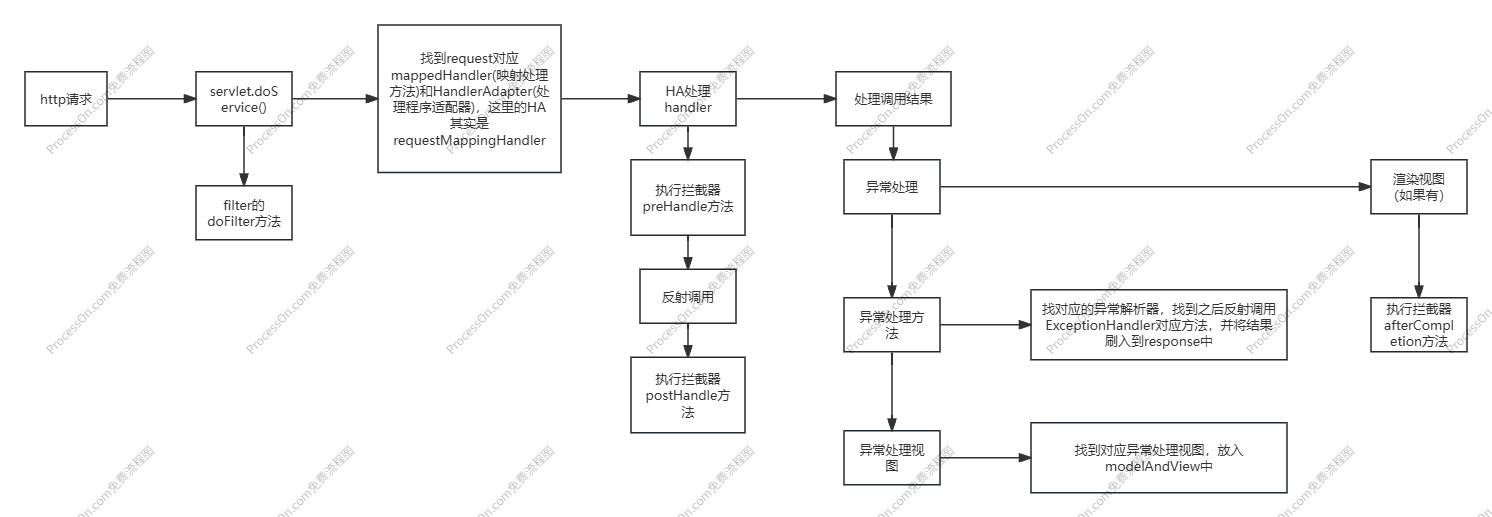
protected void doDispatch(HttpServletRequest request, HttpServletResponse response) throws Exception {
HttpServletRequest processedRequest = request;
HandlerExecutionChain mappedHandler = null;
boolean multipartRequestParsed = false;
WebAsyncManager asyncManager = WebAsyncUtils.getAsyncManager(request);
try {
try {
ModelAndView mv = null;
Exception dispatchException = null;
try {
processedRequest = this.checkMultipart(request);
multipartRequestParsed = processedRequest != request;
mappedHandler = this.getHandler(processedRequest);
if (mappedHandler == null) {
this.noHandlerFound(processedRequest, response);
return;
}
HandlerAdapter ha = this.getHandlerAdapter(mappedHandler.getHandler());
String method = request.getMethod();
boolean isGet = "GET".equals(method);
if (isGet || "HEAD".equals(method)) {
long lastModified = ha.getLastModified(request, mappedHandler.getHandler());
if ((new ServletWebRequest(request, response)).checkNotModified(lastModified) && isGet) {
return;
}
}
if (!mappedHandler.applyPreHandle(processedRequest, response)) {
return;
}
mv = ha.handle(processedRequest, response, mappedHandler.getHandler());
if (asyncManager.isConcurrentHandlingStarted()) {
return;
}
this.applyDefaultViewName(processedRequest, mv);
mappedHandler.applyPostHandle(processedRequest, response, mv);
} catch (Exception ex) {
dispatchException = ex;
} catch (Throwable err) {
dispatchException = new NestedServletException("Handler dispatch failed", err);
}
this.processDispatchResult(processedRequest, response, mappedHandler, mv, dispatchException);
} catch (Exception ex) {
this.triggerAfterCompletion(processedRequest, response, mappedHandler, ex);
} catch (Throwable err) {
this.triggerAfterCompletion(processedRequest, response, mappedHandler, new NestedServletException("Handler processing failed", err));
}
} finally {
if (asyncManager.isConcurrentHandlingStarted()) {
if (mappedHandler != null) {
mappedHandler.applyAfterConcurrentHandlingStarted(processedRequest, response);
}
} else if (multipartRequestParsed) {
this.cleanupMultipart(processedRequest);
}
}
}Spring如何解决循环依赖
Spring通过三级缓存来解决循环依赖,三级缓存的目的是在bean未初始化完成前,将引用暴露出来,三级缓存如下:
- 一级缓存:存放初始化好的Bean对象
- 二级缓存:早期引用,存放未初始化完成的Bean对象(未注入Setter属性)
- 三级缓存:工厂对象,用于创建二级缓存的早期引用
调用流程为,先查一级缓存,一级缓存不存在,再查二级缓存,二级缓存也不存在,查三级缓存。
为什么不用二级依赖,二级依赖没办法处理AOP代理问题
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
// 从一级缓存拿
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null && this.isSingletonCurrentlyInCreation(beanName)) {
// 从二级缓存拿
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null && allowEarlyReference) {
synchronized(this.singletonObjects) {
singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null) {
// 从三级缓存拿
ObjectFactory<?> singletonFactory = (ObjectFactory)this.singletonFactories.get(beanName);
if (singletonFactory != null) {
singletonObject = singletonFactory.getObject();
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
}
}
}
}
}
}
return singletonObject;
}Spring自动加载的原理
首先进入@SpringBootApplication内部,发现分别是由三个注解(@SpringBootConfiguration、@EnableAutoConfiguration、@ComponentScan)构成。其中自动装配是由@EnableAutoConfiguration来做的。@EnableAutoConfiguration使用类AutoConfigurationImportSelector来进行自动装配,流程如下:
- 扫描jar包下的META-INF/spring.factories文件
- 加载文件中对应的配置类
- 通过条件注解来决定加载哪些Bean
- @ConditionalOnBean
- @ConditionalOnClass
- @ConditionalOnProperty
@SpringBootApplication
--> 进入@SpringBootApplication
@SpringBootConfiguration
@EnableAutoConfiguration
@ComponentScan
public @interface SpringBootApplication {}
--> 进入@EnableAutoConfiguration
@AutoConfigurationPackage
@Import(AutoConfigurationImportSelector.class)
public @interface EnableAutoConfiguration {}
-->进入AutoConfigurationImportSelector类
public class AutoConfigurationImportSelector implements DeferredImportSelector, BeanClassLoaderAware,
ResourceLoaderAware, BeanFactoryAware, EnvironmentAware, Ordered {
/**
* 根据@Configuration的注解元数据返回自动配置entry
*/
protected AutoConfigurationEntry getAutoConfigurationEntry(AnnotationMetadata annotationMetadata) {
if (!isEnabled(annotationMetadata)) {
return EMPTY_ENTRY;
}
AnnotationAttributes attributes = getAttributes(annotationMetadata);
List<String> configurations = getCandidateConfigurations(annotationMetadata, attributes);
configurations = removeDuplicates(configurations);
Set<String> exclusions = getExclusions(annotationMetadata, attributes);
checkExcludedClasses(configurations, exclusions);
configurations.removeAll(exclusions);
configurations = getConfigurationClassFilter().filter(configurations);
fireAutoConfigurationImportEvents(configurations, exclusions);
return new AutoConfigurationEntry(configurations, exclusions);
}
/**
* SpringFactoriesLoader从jar的META-INF/spring.factories目录下加载元数据信息
*/
protected List<String> getCandidateConfigurations(AnnotationMetadata metadata, AnnotationAttributes attributes) {
List<String> configurations = SpringFactoriesLoader.loadFactoryNames(getSpringFactoriesLoaderFactoryClass(),
getBeanClassLoader());
Assert.notEmpty(configurations, "No auto configuration classes found in META-INF/spring.factories. If you "
+ "are using a custom packaging, make sure that file is correct.");
return configurations;
}Spring AOP是如何实现的
Spring Bean被代理的时机
在bean初始化后,被代理创建的
public abstract class AbstractAutoProxyCreator extends ProxyProcessorSupport
implements SmartInstantiationAwareBeanPostProcessor, BeanFactoryAware {
// 初始化后执行
public Object postProcessAfterInitialization(@Nullable Object bean, String beanName) {
if (bean != null) {
Object cacheKey = getCacheKey(bean.getClass(), beanName);
if (this.earlyProxyReferences.remove(cacheKey) != bean) {
// 代理包装
return wrapIfNecessary(bean, beanName, cacheKey);
}
}
return bean;
}
protected Object wrapIfNecessary(Object bean, String beanName, Object cacheKey) {
...
// Create proxy if we have advice.
// 拿到所有的advice
Object[] specificInterceptors = getAdvicesAndAdvisorsForBean(bean.getClass(), beanName, null);
if (specificInterceptors != DO_NOT_PROXY) {
this.advisedBeans.put(cacheKey, Boolean.TRUE);
// 创建代理对象
Object proxy = createProxy(
bean.getClass(), beanName, specificInterceptors, new SingletonTargetSource(bean));
this.proxyTypes.put(cacheKey, proxy.getClass());
return proxy;
}
this.advisedBeans.put(cacheKey, Boolean.FALSE);
return bean;
}
}代理实现方式
代理类有两种实现方式,JDK代理和CGLIB代理,取决于用户的配置以及被代理类的类型。默认使用CGLIB进行代理,当被代理类为接口时,使用JDK代理。
public class DefaultAopProxyFactory implements AopProxyFactory, Serializable {
public AopProxy createAopProxy(AdvisedSupport config) throws AopConfigException {
if (config.isOptimize() || config.isProxyTargetClass() || hasNoUserSuppliedProxyInterfaces(config)) {
Class<?> targetClass = config.getTargetClass();
if (targetClass == null) {
throw new AopConfigException("TargetSource cannot determine target class: " +
"Either an interface or a target is required for proxy creation.");
}
if (targetClass.isInterface() || Proxy.isProxyClass(targetClass)) {
return new JdkDynamicAopProxy(config);
}
return new ObjenesisCglibAopProxy(config);
}
else {
return new JdkDynamicAopProxy(config);
}
}
}核心概念
pointcut:切入点,
advice:执行逻辑,切入后执行的逻辑
advisor:组合pointcut和advice
methodInterceptor:方法拦截器,由advice实现
反射调用
代理对象调用invoke,先匹配看是否有advice需要执行,然后再执行invoke
final class JdkDynamicAopProxy implements AopProxy, InvocationHandler, Serializable {
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
Object oldProxy = null;
boolean setProxyContext = false;
TargetSource targetSource = this.advised.targetSource;
Object target = null;
try {
...
Object retVal;
target = targetSource.getTarget();
Class<?> targetClass = (target != null ? target.getClass() : null);
// 拿到拦截器链,其实就是所有的符合条件advice
// Get the interception chain for this method.
List<Object> chain = this.advised.getInterceptorsAndDynamicInterceptionAdvice(method, targetClass);
MethodInvocation invocation =
new ReflectiveMethodInvocation(proxy, target, method, args, targetClass, chain);
// Proceed to the joinpoint through the interceptor chain.
retVal = invocation.proceed();
...
return retVal;
}
}
}
// 动态顾问拦截器(cglib调用会到这里)
private static class DynamicAdvisedInterceptor implements MethodInterceptor, Serializable {
private final AdvisedSupport advised;
public DynamicAdvisedInterceptor(AdvisedSupport advised) {
this.advised = advised;
}
// invoke调用时会进入这个
public Object intercept(Object proxy, Method method, Object[] args, MethodProxy methodProxy) throws Throwable {
Object oldProxy = null;
boolean setProxyContext = false;
Object target = null;
TargetSource targetSource = this.advised.getTargetSource();
try {
if (this.advised.exposeProxy) {
// Make invocation available if necessary.
oldProxy = AopContext.setCurrentProxy(proxy);
setProxyContext = true;
}
// Get as late as possible to minimize the time we "own" the target, in case it comes from a pool...
target = targetSource.getTarget();
Class<?> targetClass = (target != null ? target.getClass() : null);
// 构建advice链
List<Object> chain = this.advised.getInterceptorsAndDynamicInterceptionAdvice(method, targetClass);
Object retVal;
// Check whether we only have one InvokerInterceptor: that is,
// no real advice, but just reflective invocation of the target.
if (chain.isEmpty() && Modifier.isPublic(method.getModifiers())) {
// We can skip creating a MethodInvocation: just invoke the target directly.
// Note that the final invoker must be an InvokerInterceptor, so we know
// it does nothing but a reflective operation on the target, and no hot
// swapping or fancy proxying.
Object[] argsToUse = AopProxyUtils.adaptArgumentsIfNecessary(method, args);
retVal = methodProxy.invoke(target, argsToUse);
}
else {
// We need to create a method invocation...
retVal = new CglibMethodInvocation(proxy, target, method, args, targetClass, chain, methodProxy).proceed();
}
retVal = processReturnType(proxy, target, method, retVal);
return retVal;
}
finally {
if (target != null && !targetSource.isStatic()) {
targetSource.releaseTarget(target);
}
if (setProxyContext) {
// Restore old proxy.
AopContext.setCurrentProxy(oldProxy);
}
}
}
}
// jdk代理和cglib代理都会通过这个方法拿到advice列表
public class DefaultAdvisorChainFactory implements AdvisorChainFactory, Serializable {
@Override
public List<Object> getInterceptorsAndDynamicInterceptionAdvice(
Advised config, Method method, @Nullable Class<?> targetClass) {
// This is somewhat tricky... We have to process introductions first,
// but we need to preserve order in the ultimate list.
AdvisorAdapterRegistry registry = GlobalAdvisorAdapterRegistry.getInstance();
Advisor[] advisors = config.getAdvisors();
List<Object> interceptorList = new ArrayList<>(advisors.length);
Class<?> actualClass = (targetClass != null ? targetClass : method.getDeclaringClass());
Boolean hasIntroductions = null;
for (Advisor advisor : advisors) {
if (advisor instanceof PointcutAdvisor) {
// Add it conditionally.
PointcutAdvisor pointcutAdvisor = (PointcutAdvisor) advisor;
if (config.isPreFiltered() || pointcutAdvisor.getPointcut().getClassFilter().matches(actualClass)) {
MethodMatcher mm = pointcutAdvisor.getPointcut().getMethodMatcher();
boolean match;
if (mm instanceof IntroductionAwareMethodMatcher) {
if (hasIntroductions == null) {
hasIntroductions = hasMatchingIntroductions(advisors, actualClass);
}
match = ((IntroductionAwareMethodMatcher) mm).matches(method, actualClass, hasIntroductions);
}
else {
match = mm.matches(method, actualClass);
}
if (match) {
MethodInterceptor[] interceptors = registry.getInterceptors(advisor);
if (mm.isRuntime()) {
// Creating a new object instance in the getInterceptors() method
// isn't a problem as we normally cache created chains.
for (MethodInterceptor interceptor : interceptors) {
interceptorList.add(new InterceptorAndDynamicMethodMatcher(interceptor, mm));
}
}
else {
interceptorList.addAll(Arrays.asList(interceptors));
}
}
}
}
else if (advisor instanceof IntroductionAdvisor) {
IntroductionAdvisor ia = (IntroductionAdvisor) advisor;
if (config.isPreFiltered() || ia.getClassFilter().matches(actualClass)) {
Interceptor[] interceptors = registry.getInterceptors(advisor);
interceptorList.addAll(Arrays.asList(interceptors));
}
}
else {
Interceptor[] interceptors = registry.getInterceptors(advisor);
interceptorList.addAll(Arrays.asList(interceptors));
}
}
return interceptorList;
}
}Advice的类型
beforeAdvice:前置通知、afterAdvice:后置通知、aroundAdvice:环绕通知AspectJAroundAdvice、returningAdvice:返回值通知AspectJAfterReturningAdvice、throwableAdvice:异常通知AspectJAfterAdvice
Spring 事务是如何实现的
Spring Bean生命周期
- 实例化(createBeanInstance)
- 属性填充(populateBean,比如@Autowire的处理器)
- 执行 BeanNameAware / BeanFactoryAware / ApplicationContextAware 等回调
- 执行 BeanPostProcessor#postProcessBeforeInitialization()
- 调用初始化方法(@PostConstruct、InitializingBean、init-method)
- 执行 BeanPostProcessor#postProcessAfterInitialization()
- Bean 就绪,可供使用(放入单例池)
- 容器关闭时调用销毁回调(@PreDestroy、DisposableBean、destroy-method)
Dubbo
优雅上下线的作用
Dubbo调用超时或异常后怎么处理
框架方面:dubbo层面提供了“重试”,“超时设置”,“集群容错”策略,集群容错策略可以选择“故障转移”,“快速失败”,“并行调用”,“安全失败(失败忽略异常,返回空值)”
业务方面:
- 熔断&降级:重要的,流量比较大的服务
- 幂等性保证:重试要考虑幂等
- 补偿机制:订单、支付调用失败,可以用MQ或JOB做补偿,如支付结果查询失败,通过MQ或JOB再去查询
- 监控和告警:配置Dubbo监控和告警,告警信息接入Prometheus,通知到开发
实际处理:
- 关键调用,保证幂等情况下重试,失败后加入补偿
- 非关键调用,可以选择丢弃
- 高频调用,熔断&降级,避免拖垮核心链路
Dubbo SPI是什么?为什么不用Java SPI?
Dubbo SPI支持自定义拓展,好处:按需加载,运行时动态拓展( Adaptive)和@SPI默认加载,支持类属性自动注入,IOC和AOP
对比Java SPI来说,Java SPI是一次性加载所有实现类
Dubbo本地导出的目的
相对远程调用来说,本地导出可以节省网络请求,提高性能,直接在jvm内部处理掉请求。简化测试和本地开发
Dubbo导出流程
for (ProtocolConfig protocolConfig : protocols) {
// 导出本地
exportLocal(url);
Exporter<?> exporter = PROTOCOL.export(PROXY_FACTORY.getInvoker(ref, (Class) interfaceClass, local));
exporters.add(exporter);
// 导出远程
exportRemote(url);
Exporter<?> exporter = PROTOCOL.export(PROXY_FACTORY.getInvoker(ref, (Class) interfaceClass, local));
exporters.add(exporter);
}
// 导出本地
public class InjvmProtocol{
public <T> Exporter<T> export(Invoker<T> invoker) throws RpcException {
return new InjvmExporter<T>(invoker, invoker.getUrl().getServiceKey(), exporterMap);
}
}
// 导出远程(注册中心)
public class RegistryProtocol{
public <T> Exporter<T> export(final Invoker<T> originInvoker) throws RpcException {
// 导出服务Dubbo
final ExporterChangeableWrapper<T> exporter = doLocalExport(originInvoker, providerUrl);
// 生产者url注册到注册中心
register(registryUrl, registeredProviderUrl);
return new DestroyableExporter<>(exporter);
}
}
// 导出远程(Dubbo)
public class DubboProtocol{
protected final Map<String, Exporter<?>> exporterMap = new ConcurrentHashMap<String, Exporter<?>>();
public <T> Exporter<T> export(Invoker<T> invoker) throws RpcException {
DubboExporter<T> exporter = new DubboExporter<T>(invoker, key, exporterMap);
exporterMap.put(key, exporter);
// 开启服务器
openServer(url);
}
}
// 代理工厂
public class JavassistProxyFactory{
public <T> Invoker<T> getInvoker(T proxy, Class<T> type, URL url) {
// TODO Wrapper cannot handle this scenario correctly: the classname contains '$'
final Wrapper wrapper = Wrapper.getWrapper(proxy.getClass().getName().indexOf('$') < 0 ? proxy.getClass() : type);
return new AbstractProxyInvoker<T>(proxy, type, url) {
@Override
protected Object doInvoke(T proxy, String methodName,
Class<?>[] parameterTypes,
Object[] arguments) throws Throwable {
return wrapper.invokeMethod(proxy, methodName, parameterTypes, arguments);
}
};
}
}Dubbo引用流程
private T createProxy(Map<String, String> map) {
if (shouldJvmRefer(map)) {
// 本地Jvm引用
invoker = REF_PROTOCOL.refer(interfaceClass, url);
}
else {
// 远程引用(RegistryProtocol)
invoker = REF_PROTOCOL.refer(interfaceClass, urls.get(0));
}
// 创建服务代理create service proxy(JavassistProxyFactory)
return (T) PROXY_FACTORY.getProxy(invoker, ProtocolUtils.isGeneric(generic));
}
// 导出远程(注册中心)
public class RegistryProtocol{
public <T> Invoker<T> refer(Class<T> type, URL url) throws RpcException {
// 集群故障转移
Cluster cluster = Cluster.getCluster(qs.get(CLUSTER_KEY));
return doRefer(cluster, registry, type, url);
}
private <T> Invoker<T> doRefer(Cluster cluster, Registry registry, Class<T> type, URL url) {
// 构建注册目录
RegistryDirectory<T> directory = new RegistryDirectory<T>(type, url);
// 注册到注册中心
registry.register(directory.getRegisteredConsumerUrl());
// 构建路由链
directory.buildRouterChain(subscribeUrl);
// 订阅url(路由规则,生产者地址,配置等变化会通知注册目录)
directory.subscribe(toSubscribeUrl(subscribeUrl));
// 生成Invoker
Invoker<T> invoker = cluster.join(directory);
return invoker;
RegistryInvokerWrapper<T> registryInvokerWrapper = new RegistryInvokerWrapper<>(directory, cluster, invoker);
for (RegistryProtocolListener listener : listeners) {
listener.onRefer(this, registryInvokerWrapper);
}
return registryInvokerWrapper;
}
}
public class JavassistProxyFactory extends AbstractProxyFactory {
public <T> T getProxy(Invoker<T> invoker, Class<?>[] interfaces) {
// 拿到代理类
return (T) Proxy.getProxy(interfaces).newInstance(new InvokerInvocationHandler(invoker));
}
}
// 调用者调用处理
public class InvokerInvocationHandler implements InvocationHandler {
// 这里是failoverClusterInvoker
private final Invoker<?> invoker;
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
return invoker.invoke(rpcInvocation).recreate();
}
}Dubbo服务目录-集群容错之registryDirectory
存储可用生产者的信息,比如ip,端口,服务协议等,将这些信息生成invoker对象存起来。调用时通过invoker调用就好了
- 列举可用的invoker
- 接受服务变更通知(routes路由信息,configuration配置信息,provider生产者信息)
- 刷新invoker列表(将通知的url转换为invoker)
Dubbo路由-集群容错之route
存储路由规则,链式路由。在服务目录拿到invoker时,通过路由规则对invoker进行过滤
Dubbo集群模式-集群路由之cluster
cluster存在的目的是在invokers进行服务调用时,有多个invoker,如何选择哪个invoker进行调用,出错了怎么处理,重试还是抛出异常等,目前dubbo有多个clusterInvoker:
- failoverClusterInvoker:失败自动切换,失败后重试下一个invoker
- failfastClusterInvoker:快速失败,只发起一次调用
- failsafeClusterInvoker:安全失败,忽略失败并返回默认结果
- failbackClusterInvoker:失败请求记录,定时重放,适合消息通知场景
- forkingClusterInvoker:并行请求多个服务器,有一个成功就返回成功
通过负载均衡策略,决定最终调用到哪个invoker
Dubbo调用过程
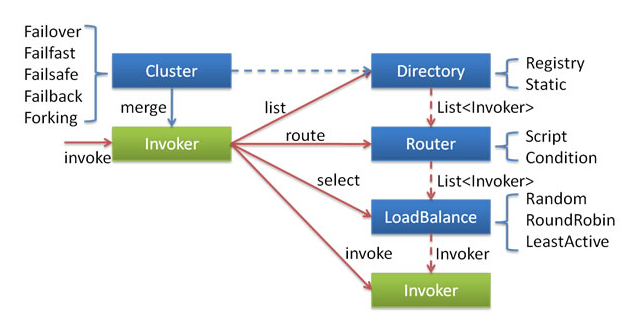
dubbo的同步请求和异步请求区别
问题排查
1.排查思路
程序慢的话,需要先分析慢在哪儿,进行优化。实在无法优化才能引入中间件(非必要不引入中间件)
平常怎么对项目优化、怎么做监控、怎么看项目有没有问题
项目难点
思路:业务理解能力、技术架构能力、系统拓展思维、风险防控意识
1.拉起支付参数
背景:有三个支付通道,建行、工行服务商、微信直连,最大程度保证成功率
主通道优先:先尝试调用主通道(建行服务商)拿去支付参数,进行缓存
失败切换:如果超时/失败,自动切换备用通道继续尝试
- 超时:可以选择重试,不切换通道
- 失败:业务异常只能切换通道,其他异常可重试
监控报警:通道成功率出现异常时进行上报(钉钉、飞书)
兜底补偿:定时任务扫描“支付参数未生成”的订单,直至拿到参数,进行缓存
支付参数缓存:拿到支付参数后,缓存到redis中
幂等性保证:无法保证、三方自己生成订单号,所以会有重复支付情况
重复支付:两个思路,一个是接收支付回调时,查看订单如果由其他通道支付,当前通道做退款处理。二是在对账环节人工退款
拓展点:路由策略(优先级、权重、失败次数后切换)
2.商品库存扣减
背景:一批skuid,批量扣除库存
内存缓存:创建商品时,将sku库存放入到缓存
高效扣减:先从redis中扣除库存(通过lua脚本),然后发送MQ消息(mysql库存扣减)
最终一致性:发送库存扣减消息,异步消费处理
3.订单幂等处理
后端生成请求token,前端携带token发起请求,请求时后端校验token是否存在,存在则删除。否则不允许请求
数据库对单号加唯一索引,防重
4.如何保证只有一个请求可以修改数据成功
加锁:加分布式锁
数据库乐观锁:修改时带上版本号,update tab set xxx = xxx where id = xxx and version = x
5.订单关单
MQ延时消息,半小时后未支付则关闭订单。定时任务进行兜底,每小时扫描前一小时订单,距现在超过半小时的订单会被关闭
6.订单异步落库
订单异步落库:使用rocketmq的事务消息,来保证落库消息发送和订单缓存Redis的原子性
- 为什么这么做
- 更好的拓展:比如创建订单后的短信通知、扣库存、记账、以及推荐系统。新业务拓展只需要订阅消息就好了
- 削峰填谷:支撑更大的并发,不至于一下打垮数据库
- 减少响应时间:减少系统的响应时间
- 可靠性:消费者挂了,消息也不会丢失。如果数据库写入失败,还要做补偿操作
线程池在项目里是怎么用的
下单页面:接口幂等,防止重复提交
发送MQ或存储redis失败,操作状态回滚
订单延时关闭:发送订单延时关闭消息 + 定时任务补偿
购物金的使用:通过分布式锁来锁定用户账户金额进行扣减
项目中线上遇到的一些问题,以及怎么排查
秒杀怎么做,库存防超卖
下单时数据异步入库,如果缓存挂了怎么办,一致性怎么保证
对es的了解,库里的数据
MySQL怎么检测慢查询,sql优化怎么做的,怎么排查,具体场景
文档,流程图,泳道图什么的
程序慢先分析慢在哪儿,进行优化,优化不了再引入中间件(非必要不引入中间件)
- 怎么分析慢
- 慢在哪儿
- 分析出来如何去优化
自研分布式日志追踪组件,是不是可以不自研。直接通过zipkin可以去完整的适配,还可以直接使用它对应的图形页面之类的
京东
在公司有没有做什么架构上的事
堆内存怎么设置的,用的什么收集器,线上问题怎么排查的
线上资损如何预防
项目难点:
职业规划,业务方向最好不要变,拓充一些业务上的认识,技术上最好有一定的追求和突破
途家
对项目的一些指标是怎么监控的
项目里哪里用到线程池了,怎么用的
项目的qps是怎样的
平常对项目做过哪些维护、监控
项目里有支付的东西,用户支付,三方平台回调消息丢了,我应该怎么补救
- 拉起支付参数的时候,设置好三方平台支付参数的过期时间
- MQ异步去查看订单是否支付,采用指数退避策略
- 若查询三方平台支付结果后,支付参数过期了,则不再处理。若订单状态被修改为已关闭,也不再处理
分库分表怎么做的,没用一些分库分表的中间件吗
自己用redis命令实现一份分布式锁代码,setnx
linux用到的命令
arraylist的扩容,数据从老数组放到新数组是深拷贝还是浅拷贝
mysql做过哪些优化
有用过es吗
待设计的东西
简历上的亮点
- 技术广度上:traceId
- 技术架构上:
待学习的东西
netty网络编程
docker file
mongo db
elasticsearch
java基础
https的原理,为什么能保证安全
synchnorize的原理,markworld
reentrantlock有多少个队列
一致性hash的原理
spring aop原理了解过吗
spring 事务的了解、事务失效的几种情况
rocketmq如何保证高并发、高性能的
分布式事务的原理
hash结构,解决hash冲突的几个点
时间复杂度和空间复杂度判断方式